今天说说关于请求与响应中的字符编码设置。
1. 字符编码问题的引入
通常web程序在接收请求并处理过程中,如果不注意编码格式及解码格式,很容易导致中文乱码,引起这个问题的原因到底在哪里?如何解决呢?
说到这个问题我们先来说一说字符集。
什么是字符集?就是各种字符的集合,包括汉字,英文,标点符号等等。各国都有不同的文字、符号。这些文字符号的集合就叫字符集。现有的字符集ASCII、GB2312、BIG5、GB18030、Unicode等。
这些字符集,集合了很多的字符,然而,字符要以二进制的形式存储在计算机中,我们就需要对其进行编码,将编码后的二进制存入。取出时我们就要对其解码,将二进制解码成我们之前的字符。这个时候我们就需要制定一套编码解码标准。否则就会导致出现混乱,也就是我们的乱码。
2. 什么是编码与解码?
就是跟加密解密一样的道理。
编码:将字符转换为二进制数
| 汉字 | 编码方式 | 编码 | 二进制 |
|---|---|---|---|
| ‘中’ | GB2312 | D6D0 | 1101 0110-1101 0000 |
| ‘中’ | UTF-16 | 4E2D | 0100 1110-0010 1101 |
| ‘中’ | UTF-8 | E4B8AD | 1110 0100- 1011 1000-1010 1101 |
解码:将二进制数转换为字符,如:
1110 0100-1011 1000-1010 1101 → E4B8AD → ’中’
乱码:一段文本,使用A字符集编码,使用B字符集解码,就会产生乱码。所以解决乱码问题的根本方法就是统一编码和解码的字符集。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8uomJsoD-1575201170606)(尚硅谷_张春胜_Servlet.assets/1558009252673.png)]](https://img-blog.csdnimg.cn/20191201200514224.png)
3. 那怎么解决请求乱码问题?
解决乱码的方法:就是统一字符编码。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-98AvOsXl-1575201170607)(尚硅谷_张春胜_Servlet.assets/1558009756944.png)]](https://img-blog.csdnimg.cn/20191201200545240.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3p4ZHNwYW9wYW8=,size_16,color_FFFFFF,t_70)
3.1 GET请求
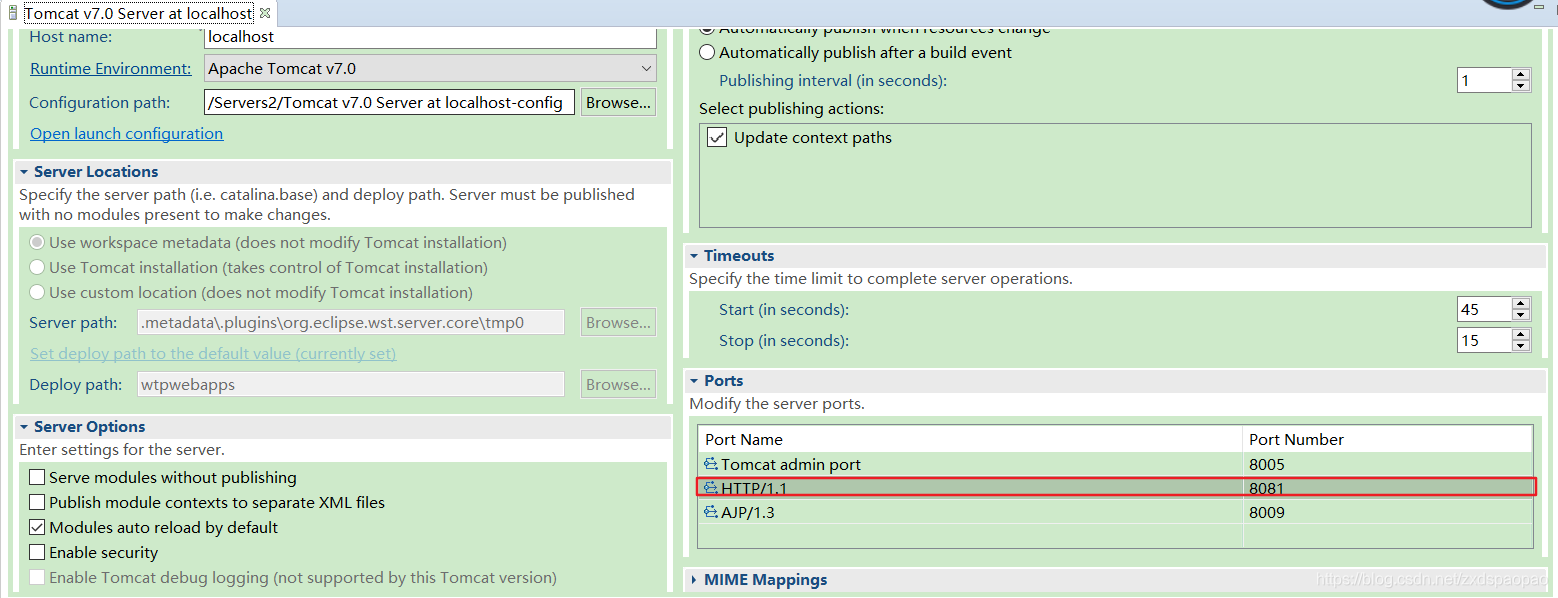
GET请求参数是在地址后面的。我们需要修改tomcat的配置文件。需要在server.xml文件修改Connector标签,添加URIEncoding="utf-8"属性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nuwBwCIv-1575201170608)(尚硅谷_张春胜_Servlet.assets/1561220531242.png)]](https://img-blog.csdnimg.cn/20191201200614791.png)
一旦配置好以后,可以解决当前工作空间中所有的GET请求的乱码问题。
3.2 POST请求
post请求提交了中文的请求体,服务器解析出现问题。
解决方法:
在获取参数值之前,设置请求的解码格式,使其和页面保持一致。
request.setCharacterEncoding("utf-8");
POST请求乱码问题的解决,只适用于当前的操作所在的类中。不能类似于GET请求一样统一解决。因为请求体有可能会上传文件。不一定都是中文字符。
4. 怎么解决响应乱码问题?
向浏览器发送响应的时候,要告诉浏览器,我使用的字符集是哪个,浏览器就会按照这种方式来解码。如何告诉浏览器响应内容的字符编码方案。很简单。
解决方法一:
response.setHeader("Content-Type", "text/html;charset=utf-8");
解决方法二:
response.setContentType("text/html;charset=utf-8");
说明:
有的人可能会想到使用response.setCharacterEncoding(“utf-8”),设置reponse对象将UTF-8字符串写入到响应报文的编码为UTF-8。只这样做是不行的,还必须手动在浏览器中设置浏览器的解析用到的字符集。