之前一直都是看,没有自己完整总结一遍,现在做一个简单的总结。
并主要针对Resnet做一个介绍。
主要参考于:
http://blog.csdn.net/app_12062011/article/details/62886113
https://www.zhihu.com/question/38499534
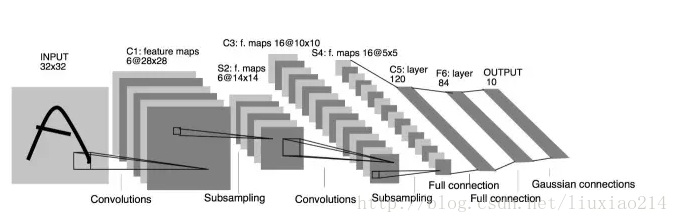
一、Lenet
第一个CNN,94年提出,98年在论文Gradient-Based Learning Applied to Document Recognition中得到实现。
使用卷积、池化(tanh或者sigmoid)、非线性映射。
二、Alexnet
2012年,在ImageNet比赛中获得第一,远甩其他网络。
特点:
引入了Relu激活函数,部分解决了sigmoid在较深网络时出现梯度弥散问题。
使用了Dropout,随机抑制一部分神经元,避免过拟合。
使用了GPU训练。
进行data argumentation,训练时随机从256x256截取224x224,并进行水平翻转;预测时,取四个角和中间位置并进行左右翻转(共10张),取平均预测效果。
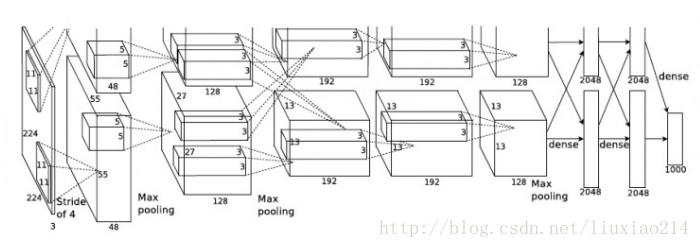
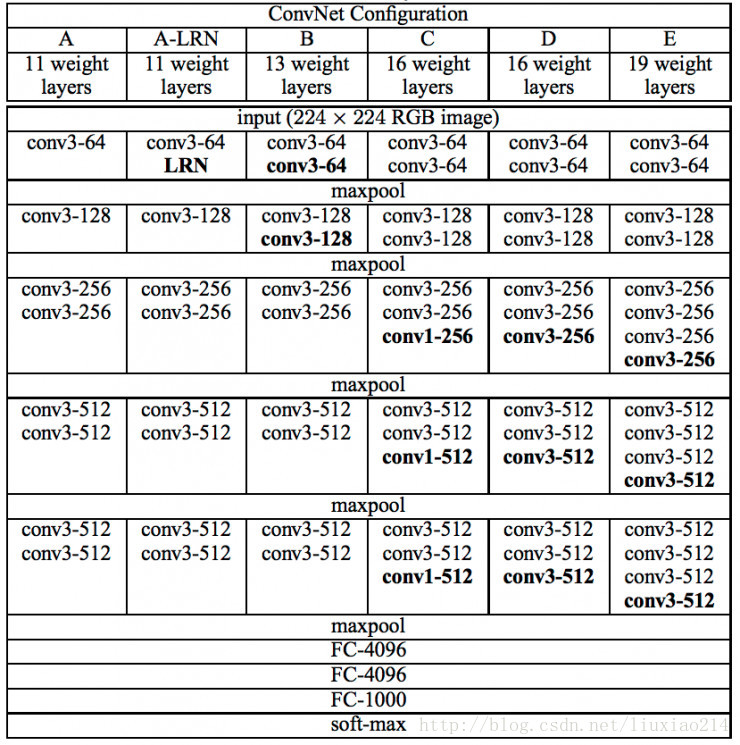
三、VGG Net
2014年,ImageNet第二名。(Very Deep Convolutional Networks for Large-Scale Image Recognition),是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的的深度卷积神经网络。
特点:
使用更小的卷积核,3X3卷积核,两个3x3卷积核相当于一个5x5卷积核,但前者比后者参数量少,并且可行进行更多地非线性变换,获得更多的复杂特征和特征组合。
提出Multi Scale,训练时将原始图像缩放至不同的S,S属于[256, 512],再随机切成224x224,做data argumentation;预测时,利用滑动窗口的形式预测,取所有窗口的平均预测值。
网络结构简洁
四、google Inception Net
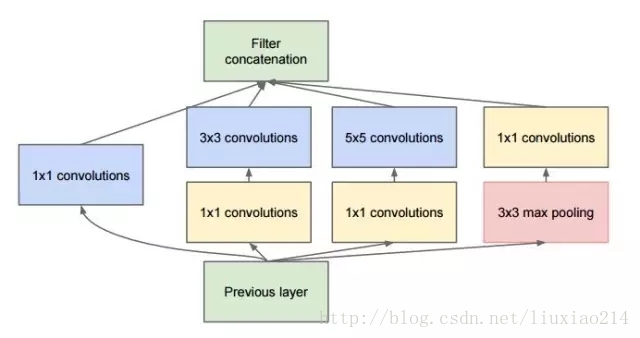
2014年,ImageNet第一名。引入Inception module。
特点:
- 采用了1x1卷积核,性价比高,用很少的计算量既可以增加一层的特征变换和非线性变换。
- 提出Batch Normalization,通过一定的手段,把每层神经元的输入值分布拉到均值0方差1的正太分布,使其落入激活函数的敏感区,避免梯度消失,加快收敛。
- 引入Inception module,4个分支结合的结构,每个分支采用1x1的卷积核。
- 去除了最后的全连接层,改用全局平均池化层来代替(图像尺寸变为1x1),即大大减少计算量。
Inception module:
五、Resnet
2015年,ImageNet第一名,(Deep Residual Learning for Image Recognition)微软的残差神经网络,引入了highway network结构,使网络变得更深。供给两个连续卷积层的输出,并分流(bypassing)输入进入下一层。
下面详细介绍一下这个网络结构。
我们已知,越深的网络一般有越高等级的特征,拥有强大的表达能力。但是事实上,在实验中,随着网络的加深,会出现两个问题:梯度弥散/消失、性能退化问题。
那如何解决呢?
提出恒等映射
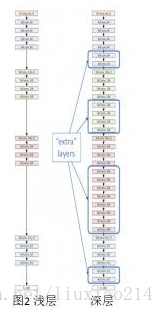
图中浅层已经得到最优效果,那么深层网络如果不能做好附加层的恒等映射,很难得到和浅层相同的的误差。(这里我有个疑问,既然深层的误差更大,为什么不直接用浅层好了,我的理解是,深层可以得到更多的特征及特征组合,如果能保持与浅层相同的误差还能得到更多的特征当然能更好的做拟合)
那如何解决这个恒等映射呢,在训练使得这些附加层的权重维持1很难做。
下图是plain 网络中的任意两层,我们希望输入x经过这两层后能够完美拟合H(x),
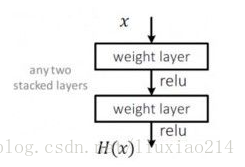
解决方法是提出Redisual 网络,下图结构,使H(x)=F(x)+x,这样只要使F(x)去拟合0就可以达到上面的要求,这里的F(x)就是残差。
而且论文中说,F(x)->0 比 x->H(x)要容易的多。(一种猜想是Relu会过滤掉小于0的信息流,加速了f(x)趋近于0。(这个结构的意思类似于传话游戏,有时人越多,又容易出错,这里就相当于多加了一个让第一个人把话传给第三个人的过程)
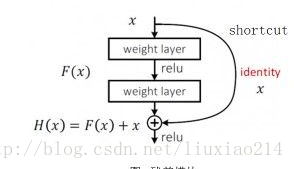
那这个结构是如何解决了梯度弥散的问题呢?网络中加入了一个x,在求梯度时,总有个导数是等于1的,这样避免了每个梯度会小于0的情况。
这里引用知乎上的一个回答:

此外,针对50层以上的resnet,改用以下结构,减训练参数。
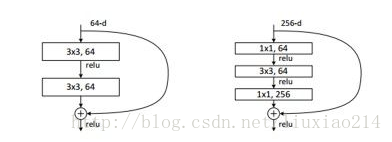
好的,到这里就介绍完resnet的原理了,随着网络深度加深,解决了梯度弥散和性能退化的问题。
一些其他理解:
1、刚开始看到resnet结构时,个人觉得与RNN、LSTM这种结构有点类似,都是保持了一些需要长期保留的信息,增加了特征信息。
2、另一理解是,很多网络并行组成了,起到了ensemble的效果。
最后,resnet的一些其他特征(这段是参考的一篇博客,但是找不出处了,如果侵权,请告知):
- 网络较深,控制了参数数量。
- 存在明显层级,特征图个数层层递进,保证输出特征的表达能力。
- 使用较少池化层,大量采用下采样,提高传播效率。
- 没有使用dropout,利用BM和全局平均池化进行正则化,加快训练速度。
- 层数较高时减少了3x3卷积核的个数,用1x1卷积核控制3x3卷积的输入输出特征map的数量。
以上。